科学家通过强化学习研究了最佳多脉冲线性交会
多脉冲轨道交会是一个经典的航天器轨迹优化问题,长期以来得到了广泛的研究。数值优化方法、深度学习(DL)方法、强化学习(RL)方法已经被提出。然而,对于数值优化方法来说,它们需要较长的计算时间,并且通常对于具有幅度约束的多脉冲交会情况无效。对于机器学习(ML)方法来说,DL方法需要大量数据,而RL方法存在效率低下的弱点。尽管如此,机器学习对短期范围的预测更为准确,而强化学习则对长期范围的预测更准确。结合两者的优点,可以对策略进行不同的预训练。在最近发表在《太空:科学与技术》上的一篇研究论文中,
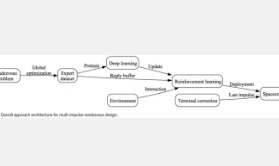
首先,作者提供了描述多脉冲线性交会问题的数学模型和所使用的 RL 算法,并提出了基于 RL 的交会设计方法。对于多脉冲线性交会问题,交会的相对运动通常由二体线性相对运动方程表示。基于线性方程组,采用约束优化来求解多脉冲交会问题,其中优化变量为脉冲矢量和脉冲时间。对于燃料最优轨道交会问题,目标函数是总速度增量;对于时间最优轨道交会问题,目标函数是交会时间。此外,脉冲幅度限制、时间限制、并制定了终端距离约束。对于 RL,目标是训练策略π ( a | s ) 学习如何映射状态s 和动作a 以便最大化奖励信号 ℛ( s , a)用于与其环境交互的代理。为此,多脉冲交会问题被认为是完全可观察的马尔可夫决策过程(MDP)。在这个强化学习中,采用了行动批评家(AC)架构,因为它在各种复杂的控制问题上具有最先进的性能。此外,优势加权AC(AWAC)算法通过使用较小的专家数据集来加速强化学习。对于所有测试的数据集大小,AWAC 始终可以比 SAC 更快地达到专家性能,并且与 IL 相比,AWAC 可以使用较小的专家数据集达到更好的性能。综上所述,假设航天器可以根据其当前状态进行机动,具有马尔可夫特性,交会设计被表述为 RL 问题。状态向量 s 的公式化反映了航天器的状态和相关问题变量。政策网络π ( a | s ) 输出基于状态的动作。动作向量a 包含脉冲和滑行周期。定义了 ℛ,燃料最佳轨道交会问题的单个时间步长的奖励或 MDP 的瞬时奖励。此外,为了获得更近的终端距离,结合RL方法使用半解析方法。整体算法方案如图2所示。
然后,作者在四种情况下研究了所提出的交会任务方法。对于随机初始状态下的燃料最优轨道交会,目标轨道随机偏心率满足[0.65,0.75]均匀分布,目标近地点高度设定为500 km。最大操纵次数设置为6,脉冲幅度限制设置为5 m/s。使用 DE 生成的 1000 条轨迹的专家数据集来加速 RL 的训练,结果表明使用专家数据集的算法可以在更少的时间步内收敛。在具有不同最大距离的随机初始状态下进行了一百次实验,以评估基于强化学习的方法的性能。与DE算法相比,基于RL的方法的燃料消耗增加了约10%;然而,计算时间不到DE算法的0.1%。对于固定初始状态下的燃料最佳轨道交会点,使用一种特殊情况,即目标和追踪器都在地球静止转移轨道附近移动。考虑两种情况:(1) 6 脉冲交会,其中 RL 策略的解与 DE 的解进行比较;(2) 20 脉冲交会,其中 RL 策略生成的控制变量用作用于进一步优化的 SQP 初始值。图 8 说明了 2 个解决方案中每个脉冲的幅度。SQP解的最后3个脉冲几乎为零,即用16个脉冲实现了燃料最佳轨道交会。相比之下,基于强化学习的解决方案具有更均匀的脉冲幅度变化。对于随机初始状态下的时间最优轨道交会点,实验场景参数与燃料最优轨道交会点场景参数相同。基于 RL 的方法仅需要 0.02% 的计算时间即可获得可行的解决方案,且奖励仅比数值优化少 15%。对于固定初始状态下的最佳时间轨道交会问题,也采用6脉冲和20脉冲轨道交会问题进行评估。表 5 显示了两种进近的滑行时间和每次机动的速度增量。由于策略网络倾向于学习一般规律,因此基于强化学习的解决方案具有更均匀的控制变量变化。基于 RL 的方法仅需要 0.02% 的计算时间即可获得可行的解决方案,且奖励仅比数值优化少 15%。对于固定初始状态下的最佳时间轨道交会问题,也采用6脉冲和20脉冲轨道交会问题进行评估。表 5 显示了两种进近的滑行时间和每次机动的速度增量。由于策略网络倾向于学习一般规律,因此基于强化学习的解决方案具有更均匀的控制变量变化。基于强化学习的方法仅需要 0.02% 的计算时间即可获得可行的解决方案,且奖励仅比数值优化少 15%。对于固定初始状态下的最佳时间轨道交会问题,也采用6脉冲和20脉冲轨道交会问题进行评估。表 5 显示了两种进近的滑行时间和每次机动的速度增量。由于策略网络倾向于学习一般规律,因此基于强化学习的解决方案具有更均匀的控制变量变化。表 5 显示了两种进近的滑行时间和每次机动的速度增量。由于策略网络倾向于学习一般规律,因此基于强化学习的解决方案具有更均匀的控制变量变化。表 5 显示了两种进近的滑行时间和每次机动的速度增量。由于策略网络倾向于学习一般规律,因此基于强化学习的解决方案具有更均匀的控制变量变化。
最后,作者得出结论。结论包括一些结论性意见。在本研究中,针对燃料最优和时间最优目标设计了单独的奖励函数。数值结果表明,经过训练的智能体可以在随机初始状态下设计具有不同目标的最佳多脉冲交会机动。该方法对于椭圆轨道附近的任意多脉冲交会是有效的,特别是在大量脉冲的情况下。所提出的方法可以快速产生比全局优化方法稍差的可行解决方案,使其成为时间敏感情况下的有吸引力的选择。训练好的智能体生成的交汇轨迹也可以作为进一步优化的初始值。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
2025年6月20日,——在世界文化遗产地河南洛阳的光影流转之间,2025年新浪微博旅游之夜盛大举行。作为国内首个...浏览全文>>
-
QQ多米试驾线下预约活动为了让更多用户感受QQ多米的独特魅力,我们特别推出了线下试驾预约活动。这不仅是一次...浏览全文>>
-
阜阳长安启源A07以其卓越的性能和豪华配置吸引了众多消费者的目光。作为一款定位高端市场的新能源车型,长安启...浏览全文>>
-
【安徽淮南大众CC新车报价2025款大公开】大众CC作为一款兼具运动感与豪华质感的轿跑车型,一直深受消费者喜爱...浏览全文>>
-
2025款长安猎手K50在安徽淮南地区的最新价格已新鲜出炉,为准备购车的朋友带来全面解析。这款车型以其高性价比...浏览全文>>
-
在安徽滁州购买长安猎手K50时,了解其落地价和省钱技巧至关重要。长安猎手K50是一款实用性强的皮卡车型,适合...浏览全文>>
-
途锐新能源是大众旗下的一款高端插电混动SUV,目前在安徽阜阳地区有售。其官方指导价约为58万元起,但实际成交...浏览全文>>
-
2025款大众CC作为一款兼具运动与豪华的中型轿车,备受关注。目前市场指导价大约在25万至35万元之间,具体价格...浏览全文>>
-
2024款探岳X作为一款备受关注的中型SUV,在市场上以其时尚的设计和出色的性能吸引了众多消费者。根据最新市场...浏览全文>>
- QQ多米试驾线下预约
- 安徽滁州长安猎手K50落地价,买车省钱秘籍
- 淮南大众CC新款价格2025款多少钱?买车攻略一网打尽
- 瑞虎8 PRO试驾,畅享豪华驾乘,体验卓越性能
- 安徽阜阳长安启源A05多少钱 2025款落地价,换代前的购车良机,不容错过
- 保时捷Macan试驾的流程是什么
- 安徽淮南大众ID.3多少钱?购车攻略在此
- 阜阳揽巡落地价,豪华配置超值价来袭
- 安徽池州威然 2024新款价格与配置的完美平衡
- 奇瑞瑞虎9试驾,新手必知的详细步骤
- QQ多米价格,换代前的购车良机,不容错过
- 池州迈腾GTE新款价格2022款多少钱?选车秘籍与优惠全公开
- 岚图追光多少钱 2024款落地价走势,近一个月最低售价25.28万起,性价比凸显
- 天津滨海威然 2024新款价格,最低售价28.98万起,入手正当时
- 蚌埠途昂新款价格2025款多少钱?购车必看
- 坦克400预约试驾全攻略
- 天津滨海ID.7 VIZZION价格,各配置车型售价全揭晓,性价比之王
- 安庆帕萨特最新价格2025款,最低售价12.35万起,入手正当时
- 亳州宝来新款价格2025款多少钱?选车指南与落地价全解析
- 生活家PHEV 2025新款价格,最低售价63.98万起现在该入手吗?