大脑激发更强大的人工智能
大多数人工智能系统都基于神经网络,其算法受到大脑中生物神经元的启发。这些网络可以由多层组成,输入来自一侧,输出来自另一侧。输出可用于做出自动决策,例如在无人驾驶汽车中。误导神经网络的攻击可能涉及利用输入层中的漏洞,但在设计防御时通常只考虑初始输入层。研究人员首次通过涉及随机噪声的过程增强了神经网络的内层,以提高其弹性。
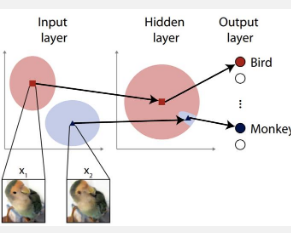
人工智能(AI)已经成为一个比较普遍的事物;您很可能拥有带有人工智能助手的智能手机,或者您使用由人工智能驱动的搜索引擎。虽然人工智能是一个广泛的术语,可以包括许多不同的方式来处理信息,有时甚至可以做出决策,但人工智能系统通常是使用类似于大脑的人工神经网络(ANN)来构建的。与大脑一样,人工神经网络有时也会因意外或第三方故意行为而感到困惑。想像一种视错觉——它可能会让你感觉自己在看一件事,而实际上你在看另一件事。
然而,让人工神经网络感到困惑的事情和可能让我们感到困惑的事情之间的区别在于,某些视觉输入可能看起来完全正常,或者至少对我们来说可能是可以理解的,但仍然可能被人工神经网络解释为完全不同的东西。
一个简单的例子可能是图像分类系统将猫误认为是狗,但更严重的例子可能是无人驾驶汽车将停车信号误认为是优先通行标志。这不仅仅是已经引起争议的无人驾驶汽车的例子;有医疗诊断系统和许多其他敏感应用程序,它们获取输入并提供信息,甚至做出可能影响人们的决策。
由于输入不一定是视觉的,因此一眼就能分析出系统可能出错的原因并不总是那么容易。试图破坏基于人工神经网络的系统的攻击者可以利用这一点,巧妙地改变预期的输入模式,使其被误解,系统将表现错误,甚至可能出现问题。有一些针对此类攻击的防御技术,但它们有局限性。东京大学医学研究生院生理学系的应届毕业生 Jumpei Ukita 和 Kenichi Ohki 教授设计并测试了一种改善 ANN 防御的新方法。
“神经网络通常由虚拟神经元层组成。第一层通常负责通过识别与特定输入相对应的元素来分析输入,”Ohki 说。“攻击者可能会提供带有伪影的图像,从而欺网络对其进行错误分类。针对此类攻击的典型防御可能是故意在第一层中引入一些噪声。这听起来违反直觉,但它可能会有所帮助,但通过这样做,它可以更好地适应视觉场景或其他输入集。然而,这种方法并不总是那么有效,我们认为可以通过超越输入层进一步深入网络内部来改善问题。”
Ukita 和 Ohki 不仅仅是计算机科学家。他们还研究了人脑,这启发他们在人工神经网络中使用他们所知道的一种现象。这不仅会向输入层添加噪声,还会向更深的层添加噪声。通常会避免这种情况,因为担心这会影响正常条件下网络的有效性。但两人发现事实并非如此,相反,噪声促进了他们的测试 ANN 的适应性,从而降低了其对模拟对抗性攻击的敏感性。
“我们的第一步是设计一种假设的攻击方法,其攻击深度比输入层更深。此类攻击需要承受输入层上具有标准噪声防御的网络的弹性。我们将这些特征空间称为对抗性示例。”Ukita 说道。“这些攻击的工作原理是故意提供远离而不是接近人工神经网络可以正确分类的输入。但诀窍是向更深层呈现微妙的误导性伪影。一旦我们证明了这种攻击的危险,我们就将随机噪声注入网络的更深层隐藏层,以提高它们的适应性,从而提高防御能力。我们很高兴地报告它有效。”
虽然新想法确实被证明是可靠的,但该团队希望进一步开发它,使其更有效地抵御预期的攻击,以及他们尚未测试过的其他类型的攻击。目前,防御仅针对这种特定类型的攻击。
“未来的攻击者可能会尝试考虑能够逃避我们在本研究中考虑的特征空间噪声的攻击,”Ukita 说。“确实,进攻和防守是一个问题的两个方面;这是一场双方都不会退缩的备竞赛,因此我们需要不断迭代、改进和创新新想法,以保护我们每天使用的系统。”
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!