新的神经网络使用常识从文本中制作假鸟图像
为了根据文本描述生成高质量图像,中国的一组研究人员构建了一个生成对抗网络,其中包含代表常识知识的数据。他们的方法使用常识来阐明图像生成的起点,也使用常识来增强生成图像在三个不同分辨率级别的不同特定特征。该网络使用鸟类图像和文本描述的数据库进行训练。与使用其他神经网络方法生成的鸟类图像相比,生成的鸟类图像获得了有竞争力的分数。
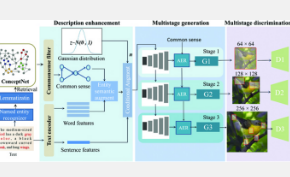
该小组的研究于 2 月 20 日发表在科学合作期刊《智能计算》(Intelligent Computing)上。
鉴于“一张图片胜过一千个单词”,当前可用的文本到图像框架的缺点不足为奇。如果你想生成一张鸟的图像,你给计算机的描述可能包括它的大小、身体的颜色和喙的形状。为了生成图像,计算机还必须决定如何显示鸟的许多细节,例如鸟面向哪个方向、背景应该是什么以及它的喙是张开还是闭合。
如果计算机拥有我们认为的常识性知识,它就会更成功地做出描述未指定细节的决定。例如,一只鸟可能用一条腿或两条腿站立,但不能用三条腿站立。
当与其前身进行定量测量时,作者的图像生成网络使用衡量保真度和与真实图像的距离的指标获得了竞争分数。定性地,作者将生成的图像描述为总体一致、自然、清晰和生动。
“我们坚信常识的引入可以极大地促进文本到图像合成的发展,”研究文章总结道。
作者用于从文本生成图像的神经网络由三个模块组成。第一个增强了将用于生成图像的文本描述。ConceptNet是一种数据源,将语言处理的一般知识表示为相关节点的图形,用于检索要添加到文本描述中的常识性知识片段。作者添加了一个过滤器来拒绝无用的知识并选择最相关的知识。为了随机化生成的图像,他们添加了一些统计噪声。因此,图像生成器的输入包括原始文本描述,作为句子和单独的单词进行分析,加上从 ConceptNet 中选择的常识知识,再加上噪声。
第二个模块分多个阶段生成图像。每个阶段对应一个图像大小,从 64 x 64 像素的小图像开始,增加到 128 x 128,然后是 256 x 256。该模块依赖于作者的“自适应实体细化”单元,它结合了常识知识每种尺寸的图像所需的详细信息。
第三个模块检查生成的图像并拒绝那些与原始描述不匹配的图像。该系统是一个“生成对抗网络”,因为它有第三部分来检查生成器的工作。由于作者的网络是“常识驱动的”,他们称他们的网络为 CD-GAN。
CD-GAN 使用Caltech-UCSD Birds-200-2011 数据集进行训练,该数据集使用 11,788 张特别注释的图像对 200 种鸟类进行了分类。
免责声明:本文由用户上传,与本网站立场无关。财经信息仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。 如有侵权请联系删除!